Overview
This document describes the high-level compiler architecture used in torch-spyre.
Compiling PyTorch programs for execution on the IBM Spyre accelerator involves two
separate compilers. The front-end compiler is an open source PyTorch Inductor extension
that is implemented as part of torch-spyre. The back-end compiler
is a proprietary compiler called DeepTools that is invoked by the front-end compiler
to generate program binaries.
The front-end compiler is responsible for the following tasks:
Op selection: mapping AI models from FX Graphs of
torchoperations to Spyre operations.Work division: breaking tensors into tiles and distributing those tiles across Spyre cores
Memory management: assigning tensors to DDR and scratchpad memories
Host code: generating the code that orchestrates device/host data transfers and kernel launches
The back-end compiler is responsible for taking the core-level specifications produced by the front-end compiler, mapping them to optimized Spyre dataflows, and producing executable programs binaries.
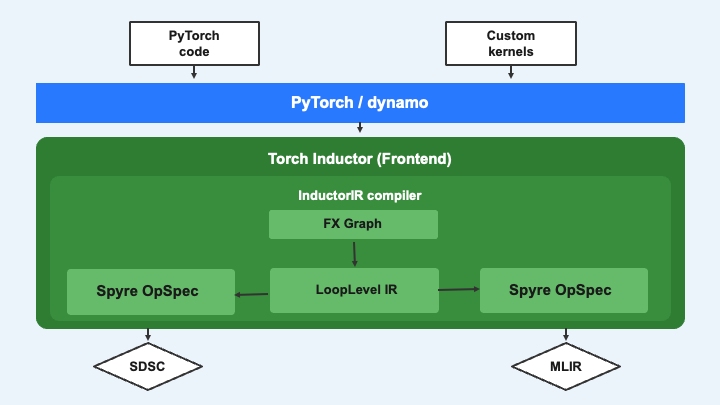
The Torch-Spyre front-end compilation stack. PyTorch programs pass through Dynamo to produce an FX graph, which Inductor lowers to LoopLevel IR. The SpyreKernel code generator compiles LoopLevel IR into an OpSpec that is in turn used to generates SDSC specifications that are the input to the backend-compiler. In a future version, we intend to replace SDSCs with a purely MLIR-based interface that includes a new KTIR MLIR dialect.
Background
A working knowledge of PyTorch’s compilers is essential for understanding our front-end compiler. Some useful resources are:
The ASPLOS’24 tutorial on PyTorch2. In particular, the portion on Inductor
General documentation on torch.compiler
Front-end Compiler Overview
The front-end compiler works by registering itself with PyTorch as the Inductor backend
for the spyre device. This causes compilation of any FX Graphs that are targeted
to a spyre device to be routed to the front-end compiler.
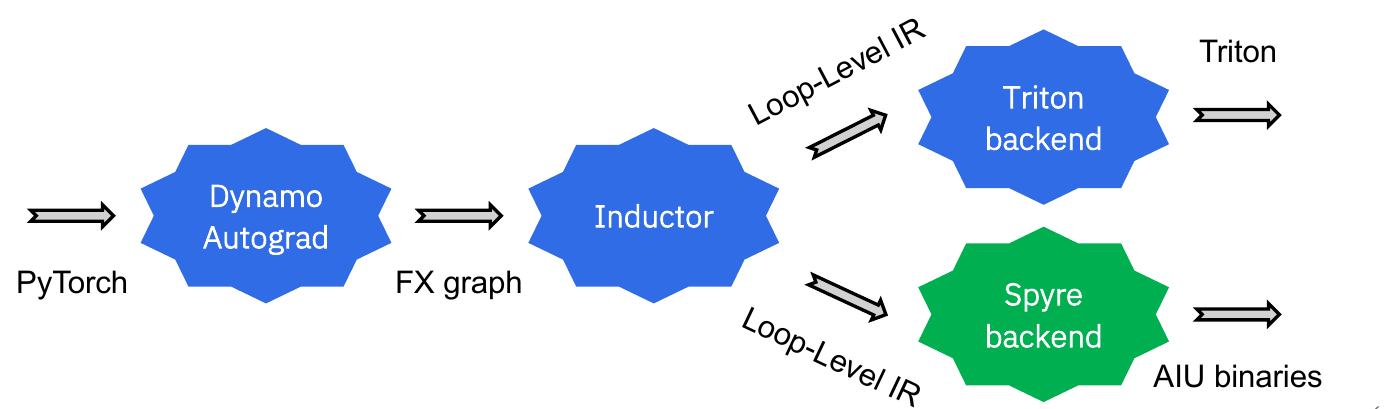
The torch.compile pipeline. Dynamo and AOTAutograd trace PyTorch programs into an FX graph of ATen operations. Inductor lowers this to Loop-Level IR and dispatches to the registered backend — either Triton (GPU) or the Torch-Spyre back-end (Spyre).
Compilation then proceeds per the normal Dynamo/Inductor compilation flow through the following stages:
The program is traced and an FX Graph constructed.
Inductor performs a number of FX Graph rewrite passes, including decompositions of complex operations into a smaller core ATen set of operations.
The FX Graph of core operations is lowered into LoopLevelIR.
A number of analysis and optimization passes are performed over the LoopLevelIR.
A final codegen pass over the LoopLevelIR generates Python code the contains both the kernels that will be compiled by the backend compiler into device binaries and the host code that will orchestrate their execution.
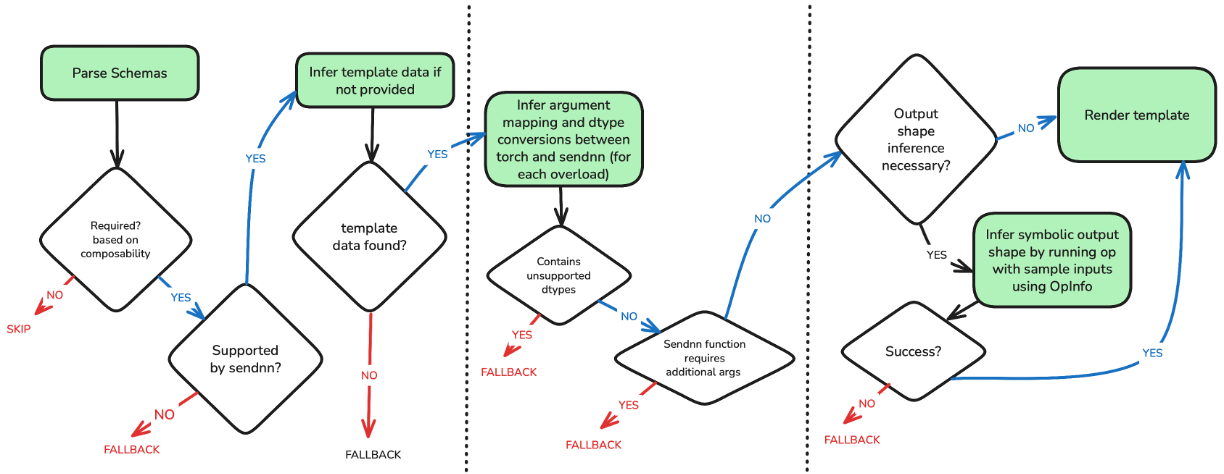
Decision flowchart for the Torch-Spyre front-end code generation pipeline. Each operation in the FX Graph is evaluated against compatibility checks, schema lookup, dtype mapping, and output shape inference before a SuperDSC template is rendered.
Some key entry points to the front-end compiler are:
__init__.py registers the compiler and customizes the configuration of Inductor.
decompositions.py is where we add Spyre-specific decompositions of existing high-level ATen operations.
customops.py is where we define new Spyre-specific operations.
passes.py is where Spyre-specific compiler passes plug into Inductor’s five exported extension points:
CustomPreGradPasses,CustomPrePasses,CustomPostPasses,CustomPreFusionPasses, andCustomPostFusionPasses. A sixth hook,CustomPreSchedulingPasses, fires just before the scheduler is built. It is not an upstream Inductor extension point yet; Torch-Spyre monkey-patchesGraphLowering._update_schedulerto invoke it (see patches.py), and we plan to propose it upstream. Both FX Graph and LoopLevelIR stages are supported.wrapper.py defines
SpyrePythonWrapperCodegen, the host-code generator that emits the Python wrapper around device kernels.spyre_kernel.py defines our compilation from LoopLevelIR into
OpSpec, our high-level description of a single operation to be performed on the device.codegen defines the compilation from an
OpSpecinto a lower-level SuperDSC json file which is the input to the backend compiler.
Additional Topics
Inductor Front-End: Deep Dive — detailed reference for passes, lowerings, decompositions, and codegen.
Back-End Compiler — the DeepTools back-end and SuperDSC format.
Adding Operations — steps to add a new supported operation to the front-end compiler.