Tensor Layouts
Although tensors appear as multidimensional arrays, computer memory is inherently one-dimensional. A tensor layout defines how multidimensional tensor indices map to positions in linear memory.
PyTorch tensors use size and stride vectors to describe this mapping. However, these are not sufficient to express the tiled layouts required by the Spyre architecture. Torch-Spyre therefore introduces Spyre tensor layouts, which extend the PyTorch representation with additional device-specific structure.
This document complements the Tiled Tensor RFC by describing the specific device memory layouts and related APIs used for tensors in Torch-Spyre.
Conceptual Overview
PyTorch tensor Spyre tensor layout Device memory
(size + stride) → (device_size + stride_map) → (sticks in DDR)
PyTorch tensors describe logical tensor structure using size and stride vectors. Spyre tensor layouts extend this model with additional device dimensions that represent the tiling and padding required by the hardware.
PyTorch Tensor Layouts
A PyTorch tensor is a multidimensional array stored in linear memory.
Rank and Dimensions
The rank of a tensor is the number of dimensions it has. The dimensions of a
PyTorch tensor are indexed by integers in range(rank).
For example, a tensor with shape (4, 6) has rank 2, with dim 0 (rows) and
dim 1 (columns).
Size and Stride
The size vector specifies the number of elements along each dimension. The stride vector specifies how many memory positions we advance when stepping one element along a given dimension.
For a tensor with shape (4, 6) stored in row-major order:
size = [4, 6]
stride = [6, 1]
This means:
Moving one column (dim 1) advances the memory offset by 1
Moving one row (dim 0) advances the memory offset by 6 (one full row)
Mapping Tensor Coordinates to Memory
The stride vector maps a tuple of tensor coordinates to a linear memory offset:
offset = lambda coordinates : np.dot(coordinates, stride)
The following example illustrates how this mapping works for a tensor with shape (4, 6) and stride (6, 1). Each cell shows the linear memory offset for that coordinate.

A 2D PyTorch tensor with shape (4, 6) and stride (6, 1). Each cell shows its linear memory offset. The stride vector maps multidimensional indices to a flat address: offset(i, j) = i × stride[0] + j × stride[1]. For element (1, 2): offset = 1×6 + 2×1 = 8 (highlighted). stride[0]=6 means stepping one row advances 6 positions in memory; stride[1]=1 means stepping one column advances 1 position.

Host (CPU) memory layout of a 2D PyTorch tensor: elements are stored in row-major order, with rows of each colour placed consecutively in a flat 1D address space. Source: Tiled Tensor RFC.
In PyTorch, the combination of the size vector and stride vector fully determines how tensor elements are arranged in memory.
Motivation for Spyre Tensor Layouts
While PyTorch layouts are flexible enough to represent many memory arrangements, they have a key limitation: a PyTorch tensor has only one stride per dimension and therefore cannot directly represent tiled memory layouts, which are required for efficient execution on Spyre.
To address this, Torch-Spyre introduces Spyre tensor layouts with higher ranks than their PyTorch counterparts. Intuitively, PyTorch tensor dimensions are split into smaller pieces to construct tiles. These tiles are then arranged into a higher-rank device tensor layout.
While strides make it possible to express padding in PyTorch tensor layouts, because Spyre tensor layouts have more dimensions, we need more dimensions of padding. Therefore, we introduce padded sizes in Spyre tensor layouts maintained separately from Pytorch sizes. Since PyTorch already maintains sizes, we only include padded sizes in a Spyre tensor layout. While we could work with strides instead, we find it easier to reason about padded sizes and order of dimensions separately rather than combining them into strides.
PyTorch often removes dimensions of size 1 because they do not affect the memory
layout. For instance, (size=[512, 1, 256], stride=[256, 256, 1]) becomes
(size=[512, 256], stride=[256, 1]). After careful consideration we concluded
that dimensions of size 1 must not contribute to the Spyre layout of a tensor.
For this reason, we say a PyTorch tensor layout is in canonical form if it has
no dimension of size 1 and canonicalize PyTorch tensor layouts before reasoning
about them. To be clear, this does not preclude selecting a different layout on
Spyre for a tensor of size [512, 1] vs. a tensor of size [512] but this will
require explicitly specifying the desired Spyre layout as the default is the same
for both.
A number of operations on Spyre produce sparse tensors, i.e., tensors with a
single element per stick. A stick is a 128-byte aligned, 128-byte contiguous
block of tensor elements in device memory. The constant BYTES_IN_STICK = 128 is defined in spyre_tensor_impl.cpp and used throughout the runtime, compiler, and tensor-layout code. At fp16 it works out to 64 elements per stick. The size lines up with the natural granularity of transfers between LPDDR5 device memory and the per-core LX scratchpad, so the hardware can pull in a full stick of contiguous elements in a single transfer.
In order to describe sparse tensor layouts we permit Spyre tensor layouts to optionally include a single synthetic dimension that does not correspond to any dimension of the PyTorch layout. This synthetic inner dimension associated with a size equal to the maximal number of elements per stick for the tensor data type will ensure that the sparse tensor has a single element of the corresponding PyTorch tensor per stick.
Per-operation stick and padding constraints
Most Spyre operations place constraints on how their operand tensors must be sticked, and on which dimensions need to be padded to a full stick. Two common cases:
Pointwise (
C = A + B). Every operand and the result must share the same stick dimension:stick(A) = stick(B) = stick(C). Partial sticks are padded out to a full stick (for example, 150 fp16 values pad to 192).Matrix multiply (
C[m, n] = A[m, k] @ B[k, n]).Ais sticked on thekdimension, whileBandCare both sticked on thendimension.B’skdimension must be padded to full sticks as well, and the padded entries on the reduction side have to be set to a neutral value (zero) before the op runs so they do not perturb the sum.
The compiler enforces these constraints during layout propagation and
inserts restickify operations or padding nodes (insert_padding in
CustomPostPasses) wherever an operand’s natural layout would not
satisfy them.
Spyre Tensor Layouts
A Spyre tensor layout extends the PyTorch layout by introducing additional dimensions that represent tiling and padding required by the hardware.

Logical (2D) view of a Spyre tiled tensor. Each row is a distinct colour; each cell represents a stick-sized chunk of 64 elements. The device layout breaks the flat PyTorch tensor into a 2D grid of tiles. Source: Tiled Tensor RFC.
A Spyre tensor has a Spyre tensor layout in addition to a PyTorch tensor layout.
A Spyre tensor layout consists of a device_size vector and a stride_map vector with the same number of elements called device_rank.
The device_rank is always greater than or equal to the rank of the (canonicalized) PyTorch tensor layout.
In combination with a PyTorch tensor layout, a Spyre tensor layout makes it possible to represent tiled tensors, sparse tensors, and padded tensors.
In contrast with a PyTorch tensor layout, a Spyre tensor has no explicit stride vector. A Spyre tensor layout is always in row-major format, i.e., the strides in the implicit stride vector are always decreasing obtained by formula:
stride[i] = math.prod(size[i+1:device_rank])
For now, a Spyre tensor layout has a unique stick dimension, which is always dimension device_rank-1. Elements in an 128-byte-aligned 128-byte stick of tensor data (in a 128-byte-aligned tensor) share the same coordinates for dimensions 0 to device_rank-2. The device_size of the stick dimension is always the maximal number of element per stick for the tensor data type.
The stride_map vector maps each device dimension to a host stride: the number
of PyTorch elements to advance in host memory when stepping one position along
that device dimension. The elements of this vector are integers where a value
of -1 indicates a synthetic or padded dimension with no corresponding host
stride (e.g. the stick dimension when the tensor size is a multiple of the
stick size, or a fully-padded expansion dimension).
For example, for a 3d PyTorch tensor of size [128, 256, 512] with
stride [131072, 512, 1] and a device_size [256, 8, 128, 64]:
device dim 0 maps to PyTorch dim 1 (stride 512)
device dim 1 maps to the tile-index part of PyTorch dim 2 (stride 64)
device dim 2 maps to PyTorch dim 0 (stride 131072)
device dim 3 maps to the within-stick part of PyTorch dim 2 (stride 1)
The corresponding stride_map is [512, 64, 131072, 1].
The stride_map is used together with device_size to derive DMA loop nests that transfer elements between host and device memory.
The relationship between PyTorch addressing and device addressing comes
out as a single identity. PyTorch computes a host offset as
offset = dot(coordinates, stride), the device computes its own offset
as device_offset = dot(device_coordinates, device_stride), and the two
are related through:
offset = dot(device_coordinates, stride_map)
In other words, the stride_map is precisely what lets you walk a tensor in device-coordinate order and still land on the right host element.
Why stride_map replaced dim_map
The first version of the Spyre layout took a different approach. It
carried a dim_map: a vector that, for each device dimension, named
the index of the PyTorch dimension it came from. For a PyTorch tensor
of shape [128, 256, 512] laid out on device as
device_size = [256, 8, 128, 64], the dim_map would be
[1, 2, 0, 2]. Read from left to right, that says device dim 0 came
from PyTorch dim 1, device dim 1 from PyTorch dim 2 (the tile-index
half of the inner dimension), device dim 2 from PyTorch dim 0, and
device dim 3 from PyTorch dim 2 again (this time the within-stick
half).
That representation reads nicely on slides, but it gets messy in the
cases the Spyre stack handles every day. Padded dimensions are the
first symptom. When the compiler rounds 150 fp16 values up to 192, or
pads B’s k-dim to a full stick for a matmul, the device dim no longer
maps cleanly back to a single PyTorch dim. A dim_map has to fall
back on a sentinel, and every pass that reads it grows a
“if it’s the sentinel, do something else” branch.
Fused and split dimensions are the second symptom. A flatten
collapses two PyTorch dims into one; a reshape can split one into
two. Tracking that with dim indices means tagging entries with
“this is the upper half of dim 2”, and the tag has to survive every
intermediate pass: work division, scratchpad planning, codegen.
Sparse Spyre layouts then add a synthetic inner dimension that has no
corresponding PyTorch dim at all. Yet another sentinel. Views without
copies make the picture even worse: when the compiler implements
transpose, flatten, or permute as a different read pattern over
the same storage, the PyTorch dim indices the view exposes have nothing
to do with the device dims of the underlying buffer, and dim_map has
to translate at every boundary.
Strides sidestep all of that. A stride is just an integer count of
“how many host elements to step by”, and that number stays meaningful
through padding, splits, fuses, synthetic dims, and views. So the
representation moved to a stride_map: one host stride per device
dimension, with -1 reserved for synthetic or fully-padded dims that
have no host counterpart. Code that walks the device-coordinate space
just dot-products with stride_map to recover the host offset, and
the special cases listed above stop needing dedicated code paths.
The compiler team puts it more directly: tensor strides are robust; tensor dimensions are not.
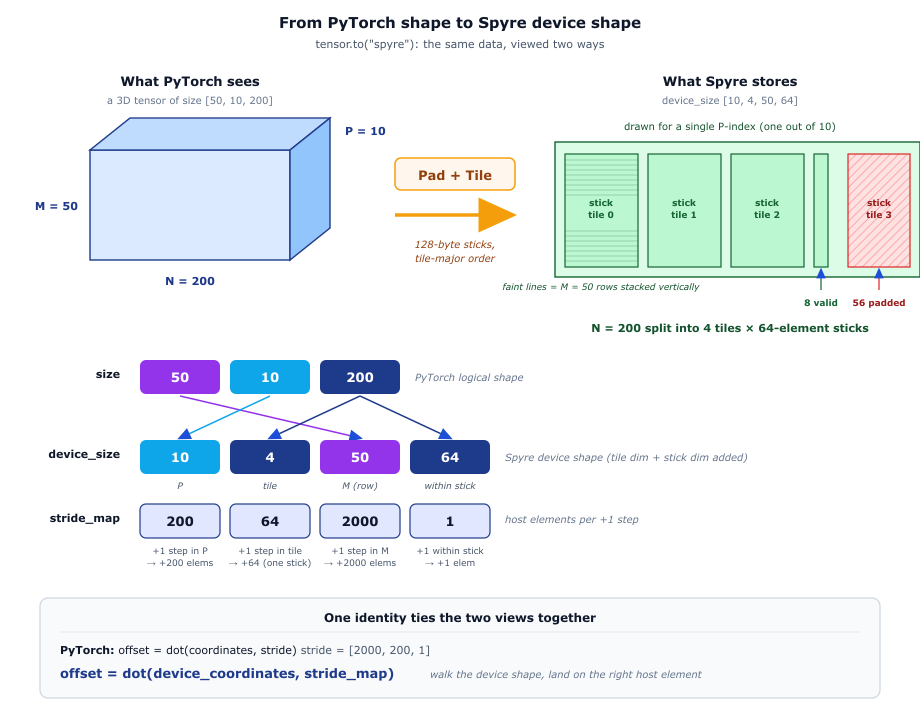
A worked end-to-end example. The same data shows up two ways: PyTorch sees a 3D tensor of size [50, 10, 200], Spyre stores it as device_size [10, 4, 50, 64]. Each stride_map entry counts the host elements you advance when you step +1 along the matching device_size dimension, and the identity offset = dot(device_coordinates, stride_map) ties the two coordinate systems together.

Device (DDR) memory layout of the same tiled tensor. Sticks are stored in device-rank row-major order: all sticks from the first tile row appear before sticks from the second, enabling efficient DMA transfers of contiguous tile slices. Source: Tiled Tensor RFC.
Dimensions in device_size may be padded. For example a Spyre tensor layout with
stride_map [512, 64, 131072, 1] and device_size [256, 8, 128, 64] may also
be used for a PyTorch tensor of size [100, 200, 500] in which case device
positions that do not map to valid host coordinates represent padding.
DMA Encoding
To transfer a tensor between host (CPU) memory and device (DDR) memory,
the runtime needs a precise mapping between the two layouts. This mapping
is encoded as three tuples of N+k integers, where N is the PyTorch
rank and k is the number of tiling dimensions:
Tuple |
Description |
|---|---|
loop ranges |
The size of each loop in the DMA nest |
host strides |
Stride in host memory for each loop index |
device strides |
Stride in device memory for each loop index |
By convention, tuples are ordered in decreasing device-stride order.
As a concrete example, a 2D row-major float16 tensor of size (1024, 256):
Each stick holds 64
float16values (128 bytes)The 256-element rows tile into 4 sticks
Host strides:
(256, 1); device strides:(64, 1)within tiles
The DMA specification for this tensor is:
((4, 1024, 64), (65536, 64, 1), (64, 256, 1)), corresponding to:
for i in range(4): # 4 tiles per row
for j in range(1024): # 1024 rows
for k in range(64): # 64 elements per stick
device[i*65536 + j*64 + k] = host[j*256 + i*64 + k]
These DCI (Data Conversion Information) specs are generated automatically by
the compiler from the SpyreTensorLayout stored in SpyreTensorImpl.
Access Patterns
Each Spyre core processes a tile — a contiguous slice of device memory. The compiler divides tensor access across cores in SPMD (Single Program, Multiple Data) fashion: all cores run the same program but on different tile ranges identified by their core ID.
Key access pattern properties:
Sticks belonging to the same tile are stored contiguously in device memory, so a tile can be staged into the scratchpad as one bulk read instead of many scattered ones
Memory access requests are limited in Spyre, so contiguous stick layout is required for full bandwidth utilization
The work division pass (see Work Division Planning) determines the tile-to-core assignment
Default Layouts and Controlling Layouts
Spyre tensors are created using two fundamental PyTorch APIs.
The
to()method is used to transfer all elements of an existing (host) tensor to a newly allocated device tensor; the result oftois the device tensor object.The
new_empty(),new_empty_strided(), etc. methods are used to create an uninitialized device tensor; the result of the method is the device tensor object. Both of these APIs can be invoked either with or without providing an explicitSpyreTensorLayout. When aSpyreTensorLayoutis provided, it specifies precisely how the device tensor will be laid out. When the APIs are invoked without providing aSpyreTensorLayoutthe device tensor is created using a default layout. Conceptually the default layout (a) designates the last dimension as the stick dimension, (b) tiles along the first dimension, and (c) pads the size of the stick dimension to make it evenly divisible into sticks.
Default Layout Example
The layout metadata is encoded by the runtime C++ class SpyreTensorLayout (see spyre_tensor_impl.h).
An instance of this class is embedded as a field in the SpyreTensorImpl class.
It can be accessed in Python via an added Tensor method device_tensor_layout().
The key elements of metadata are:
device_size: analogous to PyTorch’ssizebut with padded values and extra dimensions for tiling.stride_map: a vector of the same length asdevice_sizegiving the host stride for each device dimension (-1 for synthetic or padded dimensions).device_dtype: the datatype of the Tensor.element_arrangement: how elements are packed within a stick. Defaults toSTANDARDand appears in therepronly when it is non-standard.
As a concrete example, run the following program:
import torch
x = torch.rand(5, 100, 150, dtype=torch.float16)
y = x.to("spyre")
stl = y.device_tensor_layout()
print(stl)
You should see something like:
SpyreTensorLayout(device_size=[100, 3, 5, 64], stride_map =[150, 64, 15000, 1], device_dtype=DataFormats.SEN169_FP16)
The 3-D tensor has a 4-D device_size.
A float16 is two bytes, therefore each stick contains 64 data values.
The stick dimension of 150 has been padded to 192 and broken into two device dimensions of (3 and 64).
Specifiying Alternate Layouts
The minimal constructor for a SpyreTensorLayout takes a size and dtype and
builds a instance that encodes the default layout. This constructor
is what is used behind the scenes when the user does not specify a layout.
As an example, we can explictly request the default layout in a to by doing:
import torch
from torch_spyre._C import SpyreTensorLayout
x = torch.rand(5, 100, 150, dtype=torch.float16)
stl = SpyreTensorLayout((5, 100, 150), torch.float16)
y = x.to("spyre",device_layout=stl)
print(y.device_tensor_layout())
You should see exactly the same output as before:
SpyreTensorLayout(device_size=[100, 3, 5, 64], stride_map =[150, 64, 15000, 1], device_dtype=DataFormats.SEN169_FP16)
A second constructor of SpyreTensorLayout enables finer-grained control.
It takes the explicit host_strides and an additional dim_order, allowing
the programmer to fine-tune the layout based on their knowledge of how the
Tensor will be used in computation. (The minimal constructor computes the
default contiguous strides for you; this one requires them explicitly.)
For example, changing the constructor in the above program to
stl = SpyreTensorLayout((5, 100, 150), (15000, 150, 1), torch.float16, [1,0,2])
yields a tensor with the tiling inverted:
SpyreTensorLayout(device_size=[5, 3, 100, 64], stride_map =[15000, 64, 150, 1], device_dtype=DataFormats.SEN169_FP16)
Layout Compatibility
Spyre operations impose hard constraints on the memory layout of their inputs and outputs. The compiler enforces these during the stickification pass:
Operations such as dot product require both inputs to have identical memory layouts.
Reduction operations along the stick dimension produce sparse tensors — outputs containing a single element per stick.
The compiler performs a topological traversal of the scheduler graph, propagating layout constraints from inputs outward and raising a compile-time error if an infeasible layout is detected.
Layouts for computed tensors (ComputedBuffers) are derived via
FixedTiledLayout — a Torch-Spyre extension to Inductor’s
FixedLayout that adds a device_layout field containing the
SpyreTensorLayout. This allows Inductor’s memory planner and code
generator to use accurate on-device sizes when allocating intermediate
buffers and generating host code.
The stickification pass inserts restickify operations where needed to
reconcile incompatible layouts between adjacent operations.
Generating DCIs and SuperDSCs
For each torch.compiled function, the front-end compiler generates:
DCI (Data Conversion Information) — host-side descriptors for DMA transfers that move tensor tiles between host memory and device DDR. These are derived directly from the
SpyreTensorLayoutof each graph input and output.SuperDSC JSON — the per-kernel specification passed to the DeepTools back-end compiler. Each SuperDSC encodes the op name, input/output tensor layouts (device sizes, stride maps, dtypes), work division, and scratchpad allocations.
The code generator uses FixedTiledLayout to determine accurate device
tensor sizes for memory allocation calls in the host code, and to
generate optimized kernel loop nests that match the device’s tiled
access pattern.
Future Extensions
Gaps
Multiple stick dimensions
Multiple memory spaces
RoPE