Inductor Front-End: Deep Dive
This page provides a detailed reference for the Torch-Spyre Inductor front-end compiler. For a high-level overview of the full compilation pipeline, see Compiler Architecture.
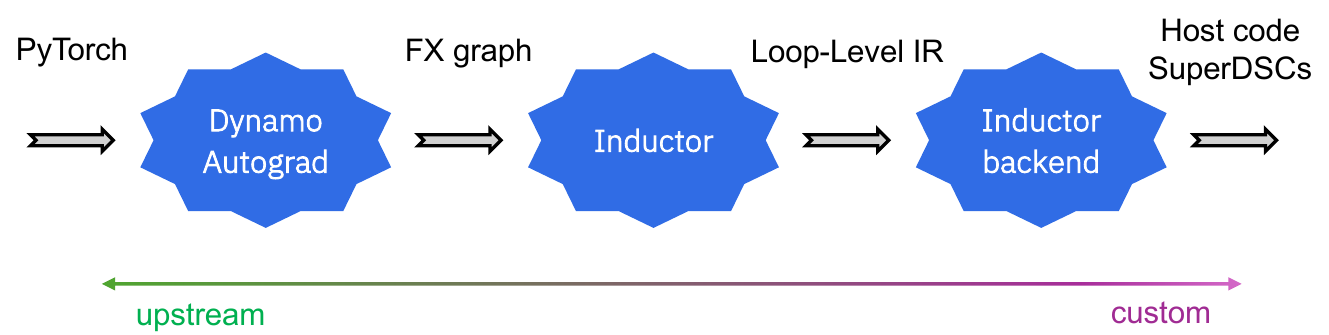
The Torch-Spyre compilation pipeline. The left end (green) is entirely upstream PyTorch — Dynamo/Autograd and Inductor. The right end (pink) is Torch-Spyre’s custom Inductor backend, which generates OpSpecs, SuperDSCs, and host code. Torch-Spyre also adds configurations and extensions to the upstream stages to tailor them for the Spyre device.
Inductor Backend Registration
At import time the Spyre backend registers three components with Inductor. Together they take the place of the Triton/CUDA codegen path on a GPU:
Component |
Module |
Role |
|---|---|---|
|
Inductor backend scheduling class. Decides how to group and order operations on the LoopLevelIR. Replaces Triton scheduling. |
|
|
Inductor wrapper-codegen class. Generates the Python wrapper that allocates tiled buffers via |
|
|
Device-specific op overrides surfaced to Inductor. |
The Spyre-specific Inductor configuration (decompositions, lowerings, the mm_to_bmm_pass that rewrites 2D matmul into 3D bmm for better core utilization, fusion heuristics, and dataflow-friendly Inductor config overrides) is activated through a single context manager:
from torch_spyre._inductor.patches import enable_spyre_context
with enable_spyre_context(...):
compiled = torch.compile(model, backend="spyre")
enable_spyre_context is the central entry point that wires everything together. The three registrations above happen earlier, at package import time, in _inductor/__init__.py.
Extending Compilation
The front-end adds compilation passes into upstream Inductor via six extension points, all registered in passes.py:
Extension Point |
Stage |
Purpose |
|---|---|---|
|
Pre-grad FX graph |
Reserved for graph rewrites before autograd partitioning. The pipeline is empty today. |
|
Post-grad FX graph (early) |
|
|
Post-grad FX graph (late) |
Late post-grad rewrites: |
|
LoopLevelIR (pre-fusion) |
Pre-fusion scheduler passes: |
|
LoopLevelIR (post-fusion) |
Post-fusion scheduler passes: |
|
LoopLevelIR (pre-scheduler) |
The pre-scheduling pipeline that runs immediately before the Scheduler is constructed (wired in via a |
FX Graph Passes
Transformations on the FX Graph tend to be simpler to implement, but happen before the layout of intermediate Tensors in device memory has been computed. Therefore they need to be layout-agnostic. Some examples of passes that are appropriate to perform at this level are:
replacing constants with size 1 tensors
normalizing matrix multiplies to add padding (also applied to
mmandbmm)
LoopLevelIR Passes
Passes on the LoopLevelIR run late in compilation. CustomPreSchedulingPasses dispatches them in a fixed order. Each step takes the GraphLowering and mutates graph.operations in place. Steps marked “Gated” are skipped when their config flag is off.
# |
Pass |
Module |
Notes |
|---|---|---|---|
1 |
|
Drops unreachable ops. |
|
2 |
|
Splits multi-op loop bodies (e.g. type conversion + arithmetic) into separate single-op buffers and materializes constant args as |
|
3 |
|
Stamps |
|
4 |
|
Checks that each op’s inputs share the same |
|
5 |
|
Moves restickify ops to better placements before the layout is finalized. |
|
6 |
|
Settles tile-structure decisions before any new restickify is inserted. |
|
7 |
|
Adds explicit re-tile ops where adjacent ops disagree on layout. |
|
8 |
|
Handles restickification for slice-mutation buffers. |
|
9 |
|
Pads |
|
10 |
|
Deduplicates identical constants and promotes shared ones. |
|
11 |
|
Propagates |
|
12 |
|
Lowers each |
|
13 |
|
Runs only when hint-derived loop groups are present. Wraps each group in nested counted loops. |
|
14 |
|
Reduces per-core access spans to fit the hardware memory budget. |
|
15 |
|
The cost-model pass claims a subset of matmuls; |
|
16 |
|
Gated by |
Once stickification has run, every ComputedBuffer carries a FixedTiledLayout, so the later passes can take device layout into account when making decisions.
For deeper treatment of individual passes see Working Set Reduction, Coarse-Tiling Loops, Work Division Planning, and Scratchpad Planning.
Views and Index Translation
Real models lean on views heavily. Here is the RoPE block from Granite:
def rope(cached_freqs, q):
q_ = q.view(2, 256, 32, 128).view(2, 256, 32, 2, 64) # B L H 2 D/2
mul_out = cached_freqs[:, :, None, :, :, :] * q_.unsqueeze(-3) # B L H 2 2 D/2
sum_out = mul_out.sum(4, keepdim=True) # B L H 2 1 D/2
return sum_out.flatten(3) # B L H D
Two view calls, an unsqueeze, a reduction, and a flatten, all on
the hot path of inference. Materializing a tensor copy at every one of
those view boundaries would erase any benefit from tiling. The rest of
this section walks through how the compiler keeps that from happening.
PyTorch models are full of view operations: reshape, view,
transpose, permute, flatten, unsqueeze, slicing, and so on. A
single transformer block in Granite goes through dozens of them.
On Spyre we want most of these views to cost nothing at runtime;
materializing a copy every time a tensor is reshaped would defeat the
point of tiling.

A worked end-to-end example. Two tensors with different PyTorch shapes
(x is rank-3, y is rank-2) both flow through one shared Inductor
index expression. The compiler then lifts that single expression into a
distinct device-coordinate vector for each tensor, and finally
co-simplifies the iteration space so the integer divisions and modulos
collapse into ordinary loop variables. The two tensors end up with
different per-argument dim orders, which SuperDSC handles natively.
Inductor gives us a useful starting point. When it lowers a graph that involves views, it normalizes everything onto a shared iteration space and emits a single per-output index expression. For example, this code:
x = torch.rand(50, 10, 200, dtype=torch.float16)
y = torch.rand(500, 200, dtype=torch.float16)
def f(x, y):
return x.flatten(0, 1) + y
result = torch.compile(f)(x.to("spyre"), y.to("spyre")).cpu()
produces an Inductor body that looks roughly like:
var_ranges = {p0: 500, p1: 200}
index0 = 200*p0 + p1
def body(self, ops):
get_index = self.get_index('index0')
load = ops.load('arg0_1', get_index)
load_1 = ops.load('arg1_1', get_index)
add = ops.add(load, load_1)
store = ops.store('buf0', get_index, add, None)
return store
Both tensors share index0 even though x was rank-3 and y was
rank-2 in the original program: the flatten was absorbed into a single
linear expression 200*p0 + p1. From here, the Spyre compiler has to
turn that one expression into per-tensor device coordinates. There
are three steps.
1. Lift index expressions to device coordinates. The host iteration
variables (p0, p1) describe positions in the PyTorch shape. They
are mapped into per-tensor device coordinate expressions that walk the
tiled, padded device shape. Continuing the example:
Host vars |
x: device shape |
y: device shape |
|---|---|---|
|
|
|
The stick dimension always comes out as a pair of expressions, one for
the tile index (floor(s/64)) and one for the intra-stick offset
(Mod(s, 64)).
2. Co-simplify the iteration space and the per-tensor coordinates.
A naive translation leaves expensive integer divisions in place. The
front-end factors the iteration space so the divisions and modulos
disappear. Splitting p into (q, p) with q = p // 10, p = p % 10
gives:
Iteration space |
x |
y |
|---|---|---|
|
|
|
Each tensor is now indexed with the same iteration variables, but the
expressions inside its coordinate vector are simple and the dim orders
are different per tensor. That is exactly what the SuperDSC IR allows
(layoutDimOrder_ is per-argument). All of this is held in
torch_spyre/_inductor/views.py
(compute_coordinates, align_tensors, normalize_coordinates).
3. Emit the OpSpec. The simplified iteration space and per-tensor
device coordinates are dropped onto the OpSpec and TensorArgs. The
“Example: an add OpSpec” section in the
Back-End Compiler doc walks through what one of these
artifacts looks like.
The net result for the user is what you would expect: ops on tensor
views run without cloning whenever the compiler can express the new
layout as a different read pattern over the same storage. When that is
not feasible (for example when a downstream op forces a different stick
dimension), the insert_restickify pass adds an explicit re-stick
operation so the rest of the pipeline still sees a clean layout.
Code Generation
We do code generation in three stages.
LoopLevelIR nodes are fused together to form Kernels.
Each Kernel is processed by spyre_kernel.py to convert it to a list of
OpSpec(op_spec.py).Finally, the codegen/ package translates
OpSpecinto SuperDSC JSON — the input format for the DeepTools back-end compiler.
Our intent is that the OpSpec will capture all important semantic information about the operation in a
more human readable form than the SuperDSC JSON. Therefore, the OpSpec should be the primary artifact
used to understand the output of the front-end compiler. Inspecting the SuperDSC JSON should only be necessary
when debugging problems in the codegen package of the front-end compiler.
Extending Operations
We extend Inductor to compile Spyre-specific operations by adding Custom Operations. We modify how existing operations are compiled by adding Spyre-specific decompositions and lowerings. See Adding Operations for a step-by-step guide.
Custom Operations
Spyre-specific operations with no ATen equivalent are defined in
customops.py
using @torch.library.custom_op. Each custom op requires:
A signature definition (
@custom_op)A fake/meta function (
@opname.register_fake)Either a lowering +
SpyreOpFuncsentry, or a decomposition that removes it from the graph before lowering
Decompositions
Spyre-specific decompositions are registered with @register_spyre_decomposition
in
decompositions.py.
Decompositions transform complex ATen operations into simpler primitives
before the graph is lowered to loop-level IR.
Lowerings
Spyre-specific lowerings to Inductor’s LoopLevelIR are defined in
lowering.py
using the @register_spyre_lowering decorator. This mechanism supports both the replacement
of upstream lowerings and the addition of new lowerings for Spyre-specific custom operations.
Module Reference
The headline modules above are the ones a contributor reaches for first. The front-end is also made up of a number of smaller modules; the table below names each and points to the source.
Module |
Purpose |
|---|---|
The six extension-point classes, plus |
|
Transitional FX-graph rewrites registered in |
|
|
|
|
|
Optimizes restickify operations inserted by layout propagation. |
|
|
|
Memory planning for Spyre device buffers. |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Shared helpers for the pre-scheduling pipeline, including |
|
|
|
|
|
|
|
Converts a fused kernel into a list of |
|
|
|
|
|
|
|
|
|
Spyre-specific Inductor configuration: |
|
|
|
Spyre-specific |
|
|
|
Indirect-access helpers for gather/scatter ops on |
|
|
|
Shared constants: |
|
|
torch.compile(..., dynamic=True) is supported through the static-binary path. Shapes are specialized at compile time and the resulting binary is reused across calls with the same input geometry.