Runtime
The Torch-Spyre runtime layer manages device lifecycle, memory allocation, and kernel execution at inference time. This section covers the device-registration plumbing, the C++ tensor and allocator machinery, eager-mode dispatch, streams, and multi-card support.
Responsibilities
Device registration — registering
spyreas a PyTorch device typeTensor memory management — allocating and freeing device DRAM (DDR) for
SpyreTensorImplobjectsDMA transfers — moving tensor data between host (CPU) memory and device (DDR) memory via the
to()/from_device()APIsKernel dispatch — loading compiled program binaries and orchestrating their execution across Spyre cores
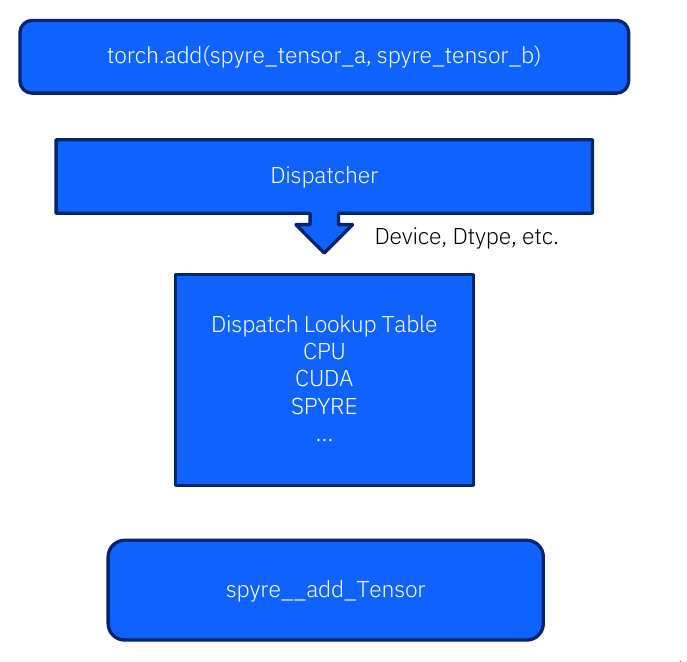
The PyTorch Dispatcher routes each operation to the correct device implementation. When a torch.add call carries Spyre tensors, the Dispatcher looks up SPYRE in its dispatch table and calls the registered spyre__add_Tensor kernel. Torch-Spyre registers all its eager runtime kernels in this table via TORCH_LIBRARY_IMPL.
Device Registration
Torch-Spyre registers spyre as a PyTorch device using the
PrivateUse1 mechanism — the standard PyTorch pathway for out-of-tree
accelerators. Registration happens in torch_spyre/__init__.py’s
_autoload():
torch.utils.rename_privateuse1_backend("spyre")
torch._register_device_module("spyre", make_spyre_module())
This gives the device a human-readable name ("spyre") without
requiring any upstream PyTorch changes. A custom
SpyreGuardImpl implements c10::impl::DeviceGuardImplInterface
to handle device management and synchronization.
Device Enumeration
torch.spyre.device_count() is handled by the PrivateUse1 hooks registered in csrc/module.cpp, which look up the visible-device set from a small group of environment variables read in csrc/spyre_device_enum.cpp:
Variable |
Effect |
|---|---|
|
Overrides the visible device count. |
|
Comma-separated list of device indices to expose. |
|
Selects the underlying flex runtime mode (PF or VF). |
The count itself comes from flex::getNumDevices.
Key C++ Components
File |
Responsibility |
|---|---|
|
pybind11 entry point for the |
|
|
|
Device tensor factory ops ( |
|
|
|
|
|
Tensor view and striding support on device, including |
|
|
|
Stream management for asynchronous execution. |
|
Visible-device enumeration. Reads |
|
C++ debug logging, gated on |
|
PyTorch Profiler (PrivateUse1) integration. |
|
SDPA dispatch. Routes |
Python Entry Point
torch_spyre/__init__.py is loaded automatically by PyTorch via the
torch.backends entry point declared in pyproject.toml. This triggers
device and backend registration without requiring an explicit import.
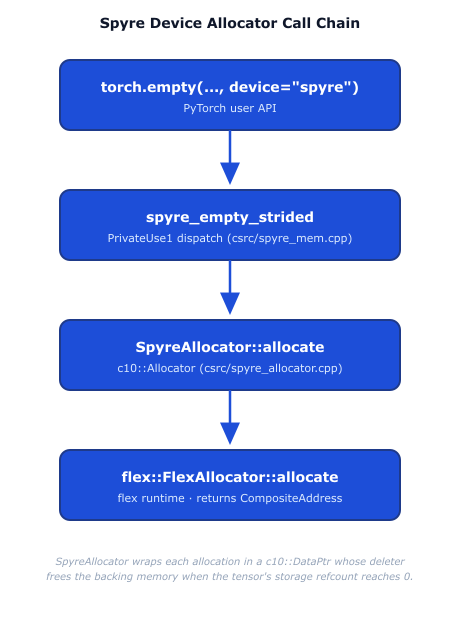
The Spyre device allocator call chain. A torch.empty(..., device="spyre") call flows through spyre_empty_strided into SpyreAllocator::allocate, which calls flex_alloc->allocate(nbytes, directive) (spyre_allocator.cpp:167).
Memory Model
Spyre tensors live in off-chip LPDDR5. Before any kernel runs, the compiler stages the tiles it needs into a much smaller on-core LX scratchpad and the kernel reads from there. The runtime, though, only deals with the LPDDR5 side. Everything below is about how a Spyre tensor in Python turns into a real LPDDR5 allocation, and how that allocation eventually finds its way back to the pool.

The two levels of memory the device sees. Full tensors stay in LPDDR5. The compiler emits load/store instructions that stage active tiles into the per-core LX scratchpad just in time for each kernel. The runtime owns the LPDDR5 allocation that backs every Spyre tensor.
For the layout that lets the runtime actually walk one of those tensors, see Tensors and Layouts. The next two sections cover what the C++ side of that looks like and how the lifetime ends.
SpyreTensorImpl
A standard PyTorch (size, stride) pair cannot describe a tiled device tensor, so Torch-Spyre defines SpyreTensorImpl as a subclass of TensorImpl. The subclass adds three members: a SpyreTensorLayout (spyre_layout) plus two standalone vectors, dma_sizes and dma_strides. Together they capture everything the runtime needs.
The SpyreTensorLayout holds:
device_size— the tensor’s shape on device, including the extra tiling and padding dims.stride_map— the host stride for each device dim. A-1here means the dim is synthetic or fully padded.device_dtype— the on-device data format, for exampleSEN169_FP16.element_arrangement— how elements are packed within a stick (defaults toSTANDARD).
Alongside the layout, SpyreTensorImpl carries dma_sizes and dma_strides directly — a host-shape DMA descriptor used when copying views back to the host. They drive copyAsync() in spyre_stream.cpp.
Note that the handles returned to Python never carry a raw device pointer. That is a hard requirement on IBM Z.

What is behind a Spyre tensor, drawn as a stack of layers. Python only ever sees the outermost at::Tensor handle. Underneath, c10::TensorImpl carries the standard tensor metadata, and the Spyre subclass adds a SpyreTensorLayout (device shape, stride_map, device dtype, and element_arrangement) plus the standalone dma_sizes/dma_strides DMA descriptor.
SpyreAllocator
SpyreAllocator (csrc/spyre_allocator.cpp) is a thin bridge between PyTorch’s c10::Allocator and flex::FlexAllocator. Every allocate(nbytes) call passes straight through to flex_alloc->allocate(nbytes) and returns a c10::DataPtr with a ReportAndDelete callback installed as its deleter. When the tensor’s storage refcount hits zero, that deleter runs, updates the DeviceStats counters, and hands the allocation back to flex. The trigger is PyTorch’s own refcount: Python’s garbage collector is not in this loop at all.
What flex_alloc->allocate(nbytes) returns is a flex::CompositeAddress, a handle that can describe contiguous or discontiguous (interleaved) device-memory regions as an ordered list of chunks. SpyreAllocator wraps it in a SharedOwnerCtx (declared in csrc/spyre_allocator.h) so the ReportAndDelete deleter can recover the original handle when freeing. The at::DataPtr Python sees never carries a raw pointer. Ownership stays on the C++ side through the shared owner.
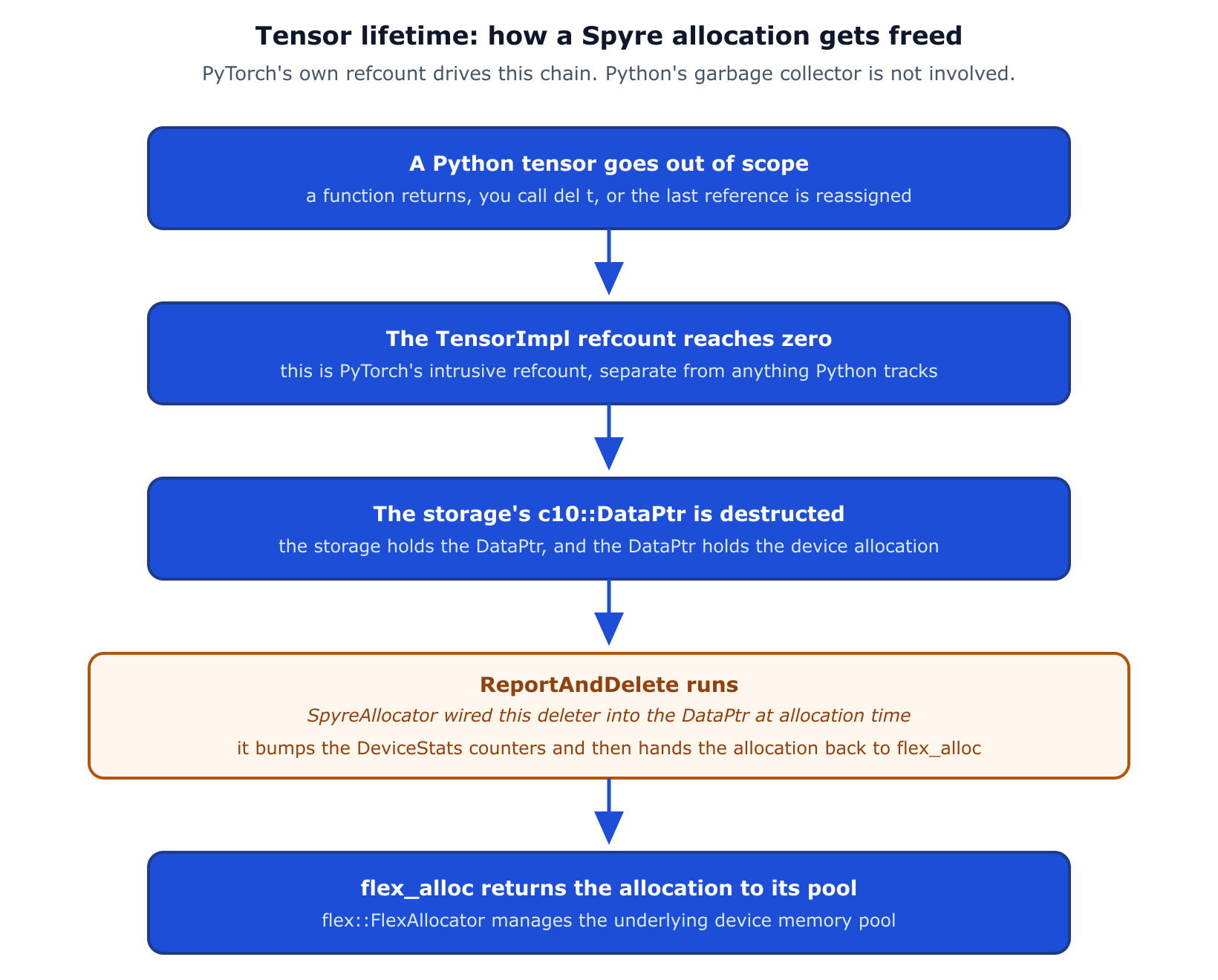
What happens between a Python tensor going out of scope and the device allocation returning to the flex pool. The piece that connects the two ends is the ReportAndDelete callback that SpyreAllocator installs on every c10::DataPtr it hands out.
When the allocator runs out of memory regions it invokes a registered
memory-pressure callback. The torch-spyre callback releases the allocator mutex,
calls PyGC_Collect() to free Python cyclic garbage, and re-acquires the mutex
before returning — allowing the allocation to be retried. See
Memory Pressure and Python GC for the full GIL
interaction and lock-ordering details.
Physical-frame (PF) and virtual-frame (VF) execution are not allocator strategies inside SpyreAllocator. The mode is picked by the FLEX_DEVICE environment variable, which configures the underlying flex runtime (see csrc/spyre_device_enum.cpp):
Mode |
Selection |
Description |
|---|---|---|
PF (Physical Frame) |
|
Direct hardware execution path. |
VF (Virtual Frame) |
|
Virtualized hardware, used in multi-tenant deployments. |
Eager Operations
Eager kernels reach the Spyre dispatch key from two Python sources.
The first is manual registrations in torch_spyre/ops/eager.py, which use register_torch_compile_kernel to register 45+ ops (arithmetic, comparison, reduction, activation, and view ops) for the PrivateUse1 dispatch key.
The second is CPU fallbacks in torch_spyre/ops/fallbacks.py, registered through @register_fallback (or the register_fallback_default helper for plain pass-throughs). These cover the long tail: arange, embedding, cumsum, tril/triu, isin, bitwise_xor/bitwise_or, argmax, and similar.
Inductor decompositions registered through register_spyre_decomposition also dispatch eagerly when the underlying ATen op does not already have a PrivateUse1 kernel. See the supported operations table for the full list.
C++ kernels can still be registered through the usual TORCH_LIBRARY_IMPL block, but most of the public eager surface today comes from the Python sources above.
Streams
Torch-Spyre supports stream-based asynchronous execution, following the
same API pattern as torch.cuda streams:
API |
Description |
|---|---|
|
Create a new Spyre stream |
|
Pass-through helper used inside |
|
Get the current stream for the device |
|
Get the default stream for the device |
|
Wait for all operations on all streams to complete |
Streams are implemented in torch_spyre/streams.py (Python) and
csrc/spyre_stream.cpp (C++).
Stream Pool
Each device keeps a fixed pool of streams (see csrc/spyre_stream.cpp). Stream 0 is the default. Streams 1 through 32 form the low-priority pool (priority == 0); streams 33 through 64 form the high-priority pool (any non-zero priority). Each pool holds 32 streams per device and allocates round-robin.
On input, priority is a binary switch: 0 selects the low-priority pool and any non-zero value selects the high-priority pool. The Stream.priority getter does not echo the constructor value back. It reports 0 for low-priority streams and -1 for high-priority streams, matching torch.cuda.Stream.priority. The asymmetry is implemented in csrc/spyre_stream.cpp SpyreStream::priority.
SpyreCode and JobPlan
A compiled artifact reaches the runtime as a SpyreCode directory: a JSON-based
manifest plus binary blobs produced by the deeptools backend. prepareKernel
in csrc/prepare_kernel.{h,cpp} translates that directory into a JobPlan,
the runtime’s executable container for a single launch.

The SpyreCode directory is the compile-time handoff. prepareKernel translates it into a JobPlan of ordered JobPlanStep instances, and SpyreStream::launch queues the corresponding RuntimeOperations on the stream in FIFO order.
JobPlan structure
A JobPlan (declared in csrc/job_plan.h) holds an ordered list of
JobPlanStep instances. At launch time, each step constructs a
flex::RuntimeOperation via its construct(LaunchContext&) method and the
runtime queues those operations on the stream in order. The four step types
cover every operation a launch needs:
Step type |
Purpose |
|---|---|
|
Host-to-device DMA transfer |
|
Device-to-host DMA transfer |
|
Kernel execution on the device |
|
Host-side computation (used for program correction) |
SpyreStream::launch(plan, args) walks the steps, builds the
RuntimeOperation for each one, and submits them to the underlying
flex::RuntimeStream. FIFO ordering on the stream is what makes the step
sequence safe: each step completes before the next one starts.
Program correction
Compiled binaries arrive with symbolic placeholders for tensor addresses that are only known at launch (allocator output, padding, batch shape). The runtime patches them in three ordered steps:

Three ordered RuntimeOperations on a stream: a CPU callback computes the corrections into a pinned host buffer, an H2D step DMAs the buffer into the program region, and the kernel runs after reading the corrections. The same pinned buffer cycles across iterations.
JobPlanStepHostComputeruns on the host. It calls into deeptools’processComputeOnHostCommandwith compiler-supplied metadata (Hcm) and writes a small correction blob into a pinned host buffer. The closure captures the metadata, the destination CompositeAddresses, and the buffer pointer.JobPlanStepH2Dcopies that buffer into the program region on the device.JobPlanStepComputethen runs the kernel. The device-side prologue reads the corrections, patches the symbolic operands, and starts execution.
The pinned host buffer is allocated once during prepareKernel and reused
across launches. For tiled execution the same buffer cycles through every
iteration — FIFO ordering guarantees each iteration’s H2D consumes the buffer
before the next iteration’s HostCompute overwrites it.
Multi-card and distributed execution
Ensembles of up to 8 Spyre cards deliver up to 1 TB of aggregate device memory.
Cross-card collective communication is exposed through the standard PyTorch
ProcessGroup API.
The spyreccl backend
Torch-Spyre registers a c10d::Backend named spyreccl. The class is
SpyreCCLBackend in csrc/distributed/spyre_ccl.{cpp,hpp}, registered with the
process-group machinery via createSpyreCCLBackend, wired up in
_create_spyre_ccl_backend in torch_spyre/__init__.py when the user invokes
init_process_group(backend="spyreccl"). The constant
DISTRIBUTED_BACKEND_NAME = "spyreccl" is defined in torch_spyre/constants.py.
Standard usage looks like any other PyTorch distributed setup:
import torch
import torch.distributed as dist
dist.init_process_group(backend="cpu:gloo,spyre:spyreccl")
x = torch.zeros(1024, dtype=torch.float16, device="spyre")
dist.broadcast(x, src=0)
Internally, SpyreCCLBackend forwards each tensor to the closed-source
spyre_comms library, which handles the wire-level transport between cards.
The torch-spyre adapter is open. The transport library is not.

The layers between user code and the device. Green boxes are in-tree (Apache-2.0). The transport library is closed source.
Supported collectives
The following collectives are implemented today, all in synchronous (blocking) mode:
Collective |
Status |
|---|---|
|
Implemented |
|
Implemented |
|
Implemented |
|
Implemented |
|
Implemented |
|
Implemented |
|
Implemented |
asyncOp=True is rejected uniformly across these methods. The remaining
process-group entries (scatter, reduce_scatter, alltoall,
alltoall_base, _allgather_base, allreduce_coalesced) raise
SpyreCCLNotSupportedException. recvAnysource is intentionally
unsupported — the protocol overhead is high and call sites are rare.
One device per process
SpyreCCLBackend follows the one-device-per-process model. Each rank attaches
to a single Spyre device (typically torch.device(f"spyre:{os.getenv('RANK', '0')}")
in the user code). The backend reuses the rank’s existing flex runtime instance
and default stream. It does not own a separate runtime context.