Work Division Planning
Work division is the compiler stage that decides how each tensor operation runs across the Spyre cores: which slice of the iteration space each core owns, and how many cores work on the op overall. This page describes the algorithm, the hardware constraints that drive it, and how its output is consumed downstream.
What work division does
Spyre exposes 32 processing cores per card. Each operation in the
compiled graph has to be parallelised across some subset of those cores
without violating the per-core memory limits. The planner runs once per
op, looks at the iteration space, the device tensor layouts, and the
core budget (SENCORES, default 32), and writes a per-dimension split
plan onto the op. Downstream stages (codegen, the SDSC emitter,
scratchpad planning) consume that plan.
Three-pass planner overview
The planner has three responsibilities, one per pass: Pass 1 enforces the 256 MB per-core span limit, Pass 2 selects matmul splits from a cost model, and Pass 3 selects a default split for every other eligible op.
For each eligible op the planner runs three passes in order:
Pass 1, span reduction, enforces the 256 MB per-core span limit. When a tensor’s per-core span exceeds the limit, this pass commits the minimum splits needed to bring the span back under. When no tensor violates the limit, the pass leaves the op untouched.
Pass 2, cost-model matmul division, runs only on
matmulandbmmops. It enumerates feasible(b, m, n, k)splits, prices each one with an analytic runtime estimate, and selects the lowest-cost combination.Pass 3, work distribution, runs on every other eligible op and on matmuls the cost model declined. It distributes the remaining cores across the output dimensions first by decreasing size, then across at most one reduction dimension.
Every eligible op is finalised by either Pass 2 or Pass 3. Pass 1
runs first and only writes to the op when a span violation forces a
minimum split. The three passes are implemented in
work_division.py
and dispatched from CustomPreSchedulingPasses in
passes.py.
The planner only sees ops whose IR data is Pointwise or Reduction
(and excluding TopK reductions, which return early). FallbackKernel,
ExternKernel, SpyreConstantFallback, and SpyreEmptyFallback
allocation kernels are filtered out earlier and never reach the passes.
Key concepts
Iteration space
Every operation has an iteration space: the set of loop variables and
their ranges that together enumerate all output elements (for pointwise
ops) or all input elements (for reductions). The loop variables are
named c0, c1, c2, … in declaration order. For a 2D pointwise
op over an output of shape [M, N], the iteration space is
{c0: M, c1: N}. c0 is the outer loop variable that ranges over the
M output rows. c1 is the inner loop variable that ranges over the N
output columns. The op fires once per (c0, c1) pair, for a total of
M × N iterations.

A 2D pointwise op’s iteration space is the M × N grid of output cells.
Each (c0, c1) pair is one iteration. For matmul, the iteration space
adds a third variable for the reduction dimension: {c0: M, c1: K, c2: N}.
Reductions and reduction dimensions
A reduction is an operation that collapses a dimension by combining all
the elements along it into a single value. sum, max, mean, and
matrix multiplication are all reductions. The dimension that gets
collapsed is the reduction dimension: it appears in the inputs but
not in the output. Dimensions that appear in both the inputs and the
output are output dimensions.
The distinction matters because splits along the two dimension types behave differently. A split along an output dimension gives every core a disjoint slice of the output to compute independently, so no combination step is needed at the end. A split along a reduction dimension gives every core a partial sum over a slice of the reduction range, and those partial sums then have to be combined across cores (the PSUM accumulation) to produce each final output element.
Pointwise (no reduction)
out[c0, c1] = relu(in[c0, c1])
iteration space {c0: M, c1: N}
output dims c0, c1
reduction dims none
Sum along the rows
out[c1] = Σ over c0 of in[c0, c1]
iteration space {c0: M, c1: N}
output dim c1
reduction dim c0 ← collapsed in the output
Matrix multiplication A @ W
out[c0, c2] = Σ over c1 of A[c0, c1] · W[c1, c2]
iteration space {c0: M, c1: K, c2: N}
output dims c0 (= M), c2 (= N)
reduction dim c1 (= K) ← collapsed in the output
Sticks and stick variables
The unit of memory transfer between LPDDR5 and the LX scratchpad is a
stick: 128 bytes, which is 64 elements at fp16, 32 at fp32, 128 at
int8 (device_dtype.elems_per_stick()). Iteration variables whose
range maps to the innermost (stick) device dimension of some tensor are
called stick variables. Before planning, they are converted from
element counts to stick counts so core splits always align to stick
boundaries. When tensors of different dtypes share a stick variable,
the conversion uses the largest elems_per_stick across those tensors.
Per-core memory span (256 MB)
Each Spyre core has a 256 MB limit on the memory span it can address.
The per-core span for a tensor is the contiguous range of device memory
(in bytes) that a single core must read or write under a particular
split assignment. The outermost device dimension a core touches sets
the span: per_core_size × stride, where per_core_size is the number
of positions along that dimension that each core covers.
If splits are not applied, a large tensor can violate this limit. Pass 1 detects violations and computes the minimum number of slices on the responsible iteration variables that bring the span back within range. For stick variables, valid slice counts are restricted to divisors of the stick count, so each core always receives a whole number of sticks. If the same iteration variable is a stick variable for one tensor and a span variable for another and no slice count satisfies both simultaneously, the compiler raises an error at compile time.
Hardware constants
A small set of hardware constants drives every decision the planner makes.
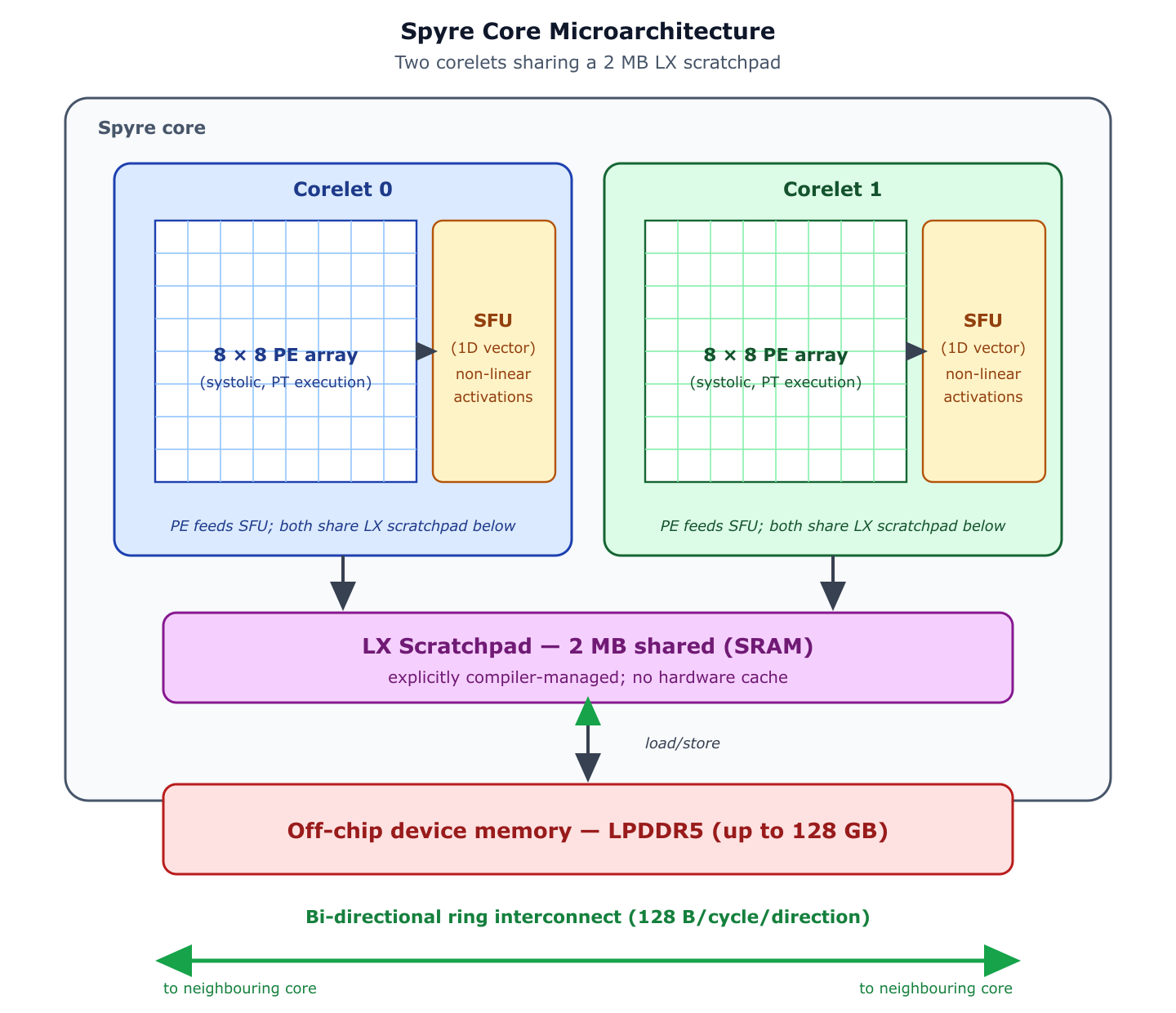
A single Spyre core has two corelets sharing a 2 MB LX scratchpad. Each corelet has an 8 × 8 systolic PE array driving the PT execution unit (so 8 PT rows per corelet) plus a 1D Special Function Unit. A card has 32 cores connected by a bi-directional ring.
Constant |
Value |
Where it shows up |
|---|---|---|
Cores per card |
32 (configurable down to 1 via |
Total core budget Pass 3 distributes |
PT rows per corelet |
8 |
Pass 2’s compute term and M tie-break |
Per-core memory span |
256 MB |
Pass 1’s correctness constraint |
Stick size |
128 B ( |
Stick-aligned splits across all passes |
For the full hardware overview see Spyre Accelerator.
Common misconceptions
The 256 MB span is not the 2 MB LX. The span limit is a per-core addressable device memory range. The 2 MB LX scratchpad is a separate on-core SRAM whose placement is decided by scratchpad planning, not work division.
Stick size is dtype dependent. A stick is always 128 bytes, but the element count comes from
device_dtype.elems_per_stick(). Code that hard-codes “64 fp16 elements” is fp16-specific.The cost-model planner does not change correctness. Pass 2’s matmul split is correct on its own. The runtime benefit of any K-split comes from a paired codegen layer in
codegen/superdsc.pythat permutes physical core IDs so K-collaborators occupy adjacent ring positions.
Pass 1 — Span Reduction (span_reduction)
This pass is mandatory and runs first over every eligible op.
For each operation, span_reduction_pass computes the minimum splits
required to keep every tensor’s per-core memory span within 256 MB
(must_split_vars).
must_split_vars processes tensors one at a time. For each tensor whose
per-core span exceeds 256 MB, it iterates over device dimensions outer
to inner and searches for the best split combination (Cartesian product
of valid divisors for the variables contributing to that dimension)
that satisfies the hardware limit. The search applies a two-tier
selection: among combinations whose total core count does not exceed
max_cores, the planner selects the combination with the largest
span that still fits within the limit (fewest cores used). If no
combination brings the span within the limit, the planner instead
selects the combination with the smallest span (most progress
toward the limit). Previously committed splits are
carried forward as lower bounds and narrow the search for subsequent
tensors.
The resulting minimum splits are written to op.op_it_space_splits via
apply_splits. If no span violation exists, op_it_space_splits is
left unset.
Splitting the outermost dim halves each core’s footprint:
A: [8192, 32768] fp16, total 512 MB
Unsplit Split K by 2
┌───────────────────────────┐ ┌──────────────┬──────────────┐
│ 512 MB per core │ │ 256 MB / core│ 256 MB / core│
│ (violates 256 MB limit) │ │ core 0 │ core 1 │
└───────────────────────────┘ └──────────────┴──────────────┘
✗ ✓
The arithmetic generalises:
per_core_span = (dim_size / split) × outer_stride × dtype_bytes. Pass 1
picks the smallest split that brings the span under 256 MB on the
outermost dimension that violates it.
Pass 2 — Cost-Model Matmul Division (cost_model_matmul_division)
Pass 2 compares feasible matmul splits and picks the one with the lowest estimated runtime. It only takes over when its choice uses at least as many cores as the default Pass 3 split would. Otherwise the op goes to Pass 3 unchanged.
The pass runs on ops whose data is a Reduction with
reduction_type == BATCH_MATMUL_OP. Every other op falls through.
When the cost model declines
The planner returns the default split unchanged in any of these cases, sending the op to Pass 3:

The cost model walks five identification checks plus one safety check. Any “no” exits to Pass 3.
The op must be a matmul or bmm (
Reductionwithreduction_type == BATCH_MATMUL_OP).span_reductionmust not have committed any split. When Pass 1 has already committed dimensions, Pass 2 declines and Pass 3 distributes the remaining cores.The output must have exactly one stickified dim (
N) and at least one row dim, soNis unambiguous.Of the row dims, exactly one must appear in a single input (this is
M). A bmm with a shared 2D weight produces two such candidates and the planner declines.The op must have exactly one reduction dim (
K).As a final safety check, if the cost-model split would use fewer cores than the default Pass 3 split, the planner declines.
When all checks pass, the planner enumerates the Cartesian product of
divisors of B, M, n_sticks, k_sticks, prices each feasible
combination whose total core count does not exceed max_cores, and
commits the argmin. The op is added to a cost_model_ops list that
Pass 3 consults to skip already-divided ops.
The cost equation
The cost is an estimated runtime in microseconds for a matmul running
with a given (b, m, n, k) split. Every term is additive, with no
multiplicative penalty:
cost(b, m, n, k) = compute + hbm + psum + shape_penalties + batch
compute, hbm, and psum model real kernel time. shape_penalties
and batch are small additive terms that break ties between
otherwise-equivalent splits. A split that uses zero cores or more than
max_cores scores inf. Lower is better.
Advanced: cost-term details
Compute time is per-core work divided by per-core peak rate:
compute = (B·M·N·K / (b·m·n·k)) / (peak_MACs_per_core × pt_eff)
pt_eff drops below 1 when the per-core M slice is short. The PT array
streams M in passes of _PT_ROWS = 8 rows, and pt_passes = (M/m) / 8.
Below the _TARGET_PT_PASSES = 5 target, startup and drain overhead is
amortised over too little work, so effective throughput falls off as
(pt_passes / 5) ** 0.25.
HBM time is bytes moved divided by aggregate LPDDR5 bandwidth, scaled by a cohort penalty:
hbm = (B·M·K + W·K·N + B·M·N) × 2 bytes / 204.8 GB/s × cohort_penalty
W is 1 for a shared 2D weight and B for a true bmm (the weight is
not replicated across batch). Each operand is broadcast to the cores
that split the orthogonal dim; up to _COHORT_LIMIT = 8 cores share a
broadcast for free. Past that, contention makes effective bandwidth
fall off as cohort_penalty = (fanout / 8) ** 0.75, where fanout is
n for a true bmm and max(m, n) for a shared weight.
PSUM time is the cost of a K-split reduction:
psum = max(0, k − 1) × (B·M·N / (b·m·n)) × psum_coeff
A K-split spreads the reduction over k cores at the cost of k − 1
partial-sum hops, charged per per-core output tile rather than the
whole output. psum_coeff is 1.0e-3 µs for a shared weight and
1.0e-4 µs for a true bmm. The term is zero when k = 1, which is why
non-K splits are usually cheaper for matmuls that are not
bandwidth-bound.
Shape and tie-break penalties are several small additive terms that separate compute-equivalent splits and bias the planner away from kernel shapes the codegen handles poorly:
The M-lane underuse term adds
10 µsper log2 step when the M split exposes fewer M lanes than the target.The M-tile underfill term adds
30 µsper log2 step when per-core rows fall below_M_TILE_UNDERFILL_TARGET = 16.The wide-N term adds
25 µsper log2 step when the per-core N tile exceeds_TARGET_N_TILE_ELEMS = 512elements.The value-matmul and shared-projection shape terms penalize splitting a small output dim against a much larger reduction dim, using size ratios rather than op names.
The core-underuse term adds a soft
150 µsper log2 step below the full core budget, so a lower-core split with good measured performance can still win.
The batch term adds a small overhead for a true-bmm batch split, because batch items are independent and gain nothing from being split across cores:
batch = log2(max(1, b)) × 10 µs # 0 for a shared weight
A shared-weight projection has no batch dim to split, so the term is zero.
The constants are defined at
work_division.py:952–979:
the peak MAC rate per core, HBM bandwidth, cohort limit and exponent,
PSUM coefficients, the tie-break weights, and the batch penalty. They are
internal tuning constants and are not user-configurable. The values are
fit to measured Spyre behaviour and re-tuned across hardware revisions.
Pass 3 — Work Distribution (work_distribution)
This pass is the default for every op Pass 2 did not claim. It runs after Pass 2 has finished across all operations.
For each remaining op, work_distribution_pass does three things:
It recovers the splits committed by Pass 1 by reading
op.op_it_space_splitsviaapply_splits_from_index_coeff. The coeff-keyed encoding is the same one codegen uses, so it remains stable across compiler passes even as sympy symbols are renamed.It ranks the remaining dimensions (those not already committed by Pass 1) for additional core assignment via
prioritize_dimensions: output dimensions first by decreasing stick-adjusted size, reduction dimensions last. At most one reduction dimension is eligible for splitting, the one that maximisescore_split(size, remaining_cores)after output dimensions have absorbed their share of cores. If Pass 1 already committed a reduction split, no further reduction dimensions are eligible.It distributes all
max_coresacross committed and priority dimensions withmulti_dim_iteration_space_split. The function first applies the committed splits as minimum requirements, then greedily assigns the largest valid divisor of each remaining dimension to the leftover core budget.
The final splits overwrite op.op_it_space_splits.
What gets written to op.op_it_space_splits
The attribute is a dict keyed by the index coefficients of the
buffer’s read and write index expressions (computed by
splits_by_index_coeff in
pass_utils.py),
with each coefficient mapping to its slice count. The coefficient
encoding is internal. Downstream passes recover an iteration-variable
view by calling
apply_splits_from_index_coeff(splits, write_index, read_index, it_space).
For the worked example below, the user-facing view is
{M: 16, N: 1, K: 2} and codegen sees the equivalent
coefficient-keyed encoding.
Two op-kind constraints apply on top of the algorithm above. For pointwise ops there is no reduction dimension, so the ranking step considers only output dimensions. For reductions, span-required splits may include at most one reduction variable. If more than one reduction variable would have to be split to satisfy the 256 MB span limit, the compiler raises an error.
Worked example: large matmul on 32 cores
Take a single matmul with A: [8192, 32768], W: [32768, 4096],
O: [8192, 4096], all fp16, on SENCORES=32. The iteration space is
{M: 8192, K: 32768, N: 4096}, with output dims M, N and reduction
dim K.
Before/after the planner
Tensor |
Unsplit per-core span |
Violating dim |
Pass 1 commit |
After Pass 3 |
Cores reading it |
|---|---|---|---|---|---|
A |
512 MB |
K (outermost) |
K split = 2 |
M = 16, K = 2 |
each core reads (512 rows) × (16384 K) = 16 MB |
W |
256 MB |
none (at limit) |
— |
M = 16, K = 2 |
each core reads (16384 K) × (4096 N) = 128 MB |
O |
64 MB |
none |
— |
M = 16, K = 2 |
each core writes (512 rows) × 4096 = 4 MB |
Pass 2 detects that Pass 1 already committed a split (K = 2). The
cost-model planner declines whenever committed_splits is non-empty,
and Pass 3 distributes the remaining cores. Without the Pass-1 commit,
the planner would enumerate divisors of (B, M, N, K) and price each
feasible combination with the cost equation.
Pass 3 inherits the 2-way K split from Pass 1. With 16 cores remaining
per K-slice, it ranks output dims by size (M = 8192, N = 4096) and
assigns all 16 cores to M. Final split: {M: 16, N: 1, K: 2}.
Dim |
Size |
Split |
Per-core |
|---|---|---|---|
M |
8192 |
16 |
512 rows |
N |
4096 |
1 |
4096 cols |
K (reduction) |
32768 |
2 |
16384 |
Core grid
The 32 cores form a 16 × 2 grid: 16 along M, paired up across the K
split. The codegen-side permutation in codegen/superdsc.py (see
Codegen pairing for K-splits)
arranges the K-collaborators on adjacent ring positions, so
(c0, c1) accumulate M-slice 0, (c2, c3) accumulate M-slice 1,
and so on:
M-slice: 0 1 2 3 4 5 6 7 ... 15
┌────┬────┬────┬────┬────┬────┬────┬────┬─────┬────┐
K = 0.. │ c0 │ c2 │ c4 │ c6 │ c8 │c10 │c12 │c14 │ ... │c30 │
K = 1.. │ c1 │ c3 │ c5 │ c7 │ c9 │c11 │c13 │c15 │ ... │c31 │
└────┴────┴────┴────┴────┴────┴────┴────┴─────┴────┘
↑
PSUM(c_{2i}, c_{2i+1}) → row i
(K-pair on adjacent ring positions,
so the PSUM hop count is 1)
A small-M, narrow-N counterexample
Switch to A: [8, 1024], W: [1024, 1024] on 32 cores. Pass 1 commits
nothing (no span violation). Pass 2 enumerates divisors of M = 8,
n_sticks, and k_sticks, prices each feasible combination, and
commits the argmin. Pass 3 skips the op.
Interaction with SDSC and scratchpad planning
Codegen pairing for K-splits
When any planner selects a K-split, the SDSC emitter permutes physical
core IDs so the cores collaborating on the K reduction occupy adjacent
ring positions. The permutation is implemented in
_k_fast_core_to_slice_mapping in codegen/superdsc.py, gated by
_should_use_k_fast_mapping. It drops PSUM accumulation hops from
m × n to 1, which is what makes cross-core K reductions cheap at
runtime. The flag SPYRE_CORE_ID_K_FAST_EMISSION (default on)
controls this codegen-side permutation. The name is legacy from when
k-fast was also a planner. The permutation runs whenever any planner
picks a K-split.
Scratchpad planning
Each pass plans one op at a time. When two adjacent ops share a tensor but select different per-core splits for it, the LX scratchpad planner sees a core-division mismatch and disqualifies the shared tensor from scratchpad reuse. The tensor is then routed through a DDR round-trip on the boundary, even though it could have stayed on-core.
Aligned splits (LX reuse possible) Mismatched splits (DDR round-trip)
────────────────────────────────── ──────────────────────────────────
Op A: split M=4, N=8 Op A: split M=4, N=8
│ │
▼ ▼
┌──────────┐ ┌──────────┐
│ tensor T │ stays on LX │ tensor T │ spills to DDR
└──────────┘ └──────────┘
│ │
▼ ▼
Op B: split M=4, N=8 Op B: split M=2, N=16
✓ reuse ✗ DDR reload
A graph-aware co-optimisation pass is in development. It aligns splits across adjacent ops to grow the LX planner’s legal-reuse set. The work is tracked in the scratchpad planning doc.
User Work-Division Hints
Users can override the automatic work-distribution choice with
spyre_hint(work_div={...}). The hint dictionary maps named tensor dimensions
to the requested number of core slices for that dimension:
from torch_spyre._inductor import spyre_hint
from torch_spyre._inductor.propagate_named_dims import (
declare_tensor_dim,
name_tensor_dims,
)
declare_tensor_dim("M", M)
declare_tensor_dim("K", K)
declare_tensor_dim("N", N)
name_tensor_dims(x, ["M", "K"])
name_tensor_dims(y, ["K", "N"])
def fn(x, y):
with spyre_hint(work_div={"M": 2, "K": 4}):
return x @ y
The compiler resolves each user-facing name onto the concrete iteration
variables for each operation in the hint scope. Coarse-tiling hints are kept
separate, so spyre_hint(tiles={...}) and spyre_hint(work_div={...}) can
coexist in the same scope.
When the work-division planner sees a resolved user hint, it validates the
request and commits the accepted splits directly instead of running the
automatic priority-based distribution. Hinted dimensions are considered in user
priority order. If adding a later split would exceed SENCORES, the compiler
logs a warning and skips that split. For matmul reductions, a user hint also
bypasses the analytic cost-model split selection; the hint takes ownership of
the accepted split decision. Validation checks that:
every split value is a positive integer
accepted splits do not exceed
SENCORESevery accepted split evenly divides the stick-adjusted dimension size
at most one accepted reduction dimension is split
User work-division hints are intentionally authoritative. If Pass 1
(span_reduction) already committed minimum splits for the 256 MB span limit,
and the user hint asks for fewer splits, the compiler logs a warning and applies
the strict user hint. warn_if_per_core_overflow then logs a critical message if
the resulting per-core span exceeds the hardware limit.
Set SPYRE_INDUCTOR_IGNORE_HINTS=1 to ignore spyre_hint(work_div={...})
annotations and use the automatic work-distribution planner.
Limitations and Future Work
Current limitations:
Dimensions must divide evenly by the slice count (no uneven splits).
Named work-division hints are reliable for dimensions that remain distinct iteration-space dimensions. Hints that target component names inside a reshaped compound dimension, such as reshaping
[B, M, K]to[B*M, K]before matmul and hintingwork_div={"M": ...}, are not guaranteed to map to the requested component yet.Only
PointwiseandReductionIR nodes are dispatched for work division.ExternKernelandFallbackKernelnodes are skipped.TOPK reductions currently run single-core, so
work_divhints on TOPK operations are ignored with a warning.Each pass plans one op at a time. Adjacent ops can pick incompatible per-core splits for a shared tensor, which the LX scratchpad planner then treats as a core-division mismatch.
The cost-model planner declines on bmms with a shared 2D weight, because pricing the broadcast of the shared weight needs weight-rank awareness the current cost function does not have. Those bmms fall through to Pass 3.
Padding is approximated rather than retrieved from the layout (FIXME in
adjust_it_space_for_sticks). Improved padding handling is being added in #2359.
Potential future enhancements:
Add a graph-aware co-optimisation pass that aligns splits across adjacent ops to grow the LX legal-reuse set (see Scratchpad planning).
Extend optimisation across operations to take data reuse and the wider memory hierarchy into account.
Make the cost model bmm-aware so it can price shared-weight bmms correctly instead of declining.
Validate the cost-model constants against more matmul shape sweeps and re-tune them as new Spyre hardware revisions are released.
See Also
Tensor Layouts covers device layouts and the stick memory model.
Scratchpad Planning covers LX placement and the co-optimisation work.
Spyre Accelerator gives the full hardware overview.