Key concepts
This page introduces the terms and ideas that the rest of the documentation assumes you have seen at least once: dataflow execution, sticks and tiled tensors, the LX scratchpad, the eager and compiled paths, graph breaks, and the four-layer op coverage strategy. Each section is short on purpose. Cross-references at the end of each section point to the deeper treatment of each topic.
For the full design narrative, see How Torch-Spyre works. For a one-line definition of a specific term, see the glossary.
1. Execution model
A GPU executes thousands of threads in lock-step on different data, the Single Instruction, Multiple Threads (SIMT) model. Spyre executes a dataflow graph instead: each operation fires as soon as its inputs are ready, and the schedule is fixed at compile time. There is no runtime thread dispatcher and no hardware cache. Execution latency is deterministic as a result.

Illustrative comparison of per-step latency. GPU execution sees jitter from thread scheduling, cache evictions, and dynamic dispatch. The compiler-planned dataflow on Spyre produces a flat latency profile for the same model.

Dataflow firing rule: an operation runs as soon as all of its inputs are available. Two independent branches execute in parallel; a join node waits for both before firing.
Every decision a GPU runtime makes (which core runs what, when data moves, where it resides) is made by the Torch-Spyre compiler. See Dataflow Accelerator Architecture for the full treatment.
2. Hardware
A Spyre card has 32 cores. Each core has 2 corelets that share a 2 MB LX scratchpad. Inside each corelet is an 8×8 PE array (systolic, used for matmul-style compute on the PT unit) and a 1D SFU/SFP vector unit (used for non-linear ops such as GELU and softmax). Cores connect via a bi-directional ring at 128 B per cycle per direction.

One Spyre core. The two corelets each have a PE array and an SFU, sharing the 2 MB LX scratchpad. The card has 32 cores connected by a ring.
The constant SENCORES controls how many cores the compiler targets
(default 32; can be lowered for debugging via the SENCORES env var).
Default dtype is torch.float16.
3. Memory hierarchy
Spyre has two memory tiers. LPDDR5 is 128 GB of off-chip device memory, equivalent in role to a GPU’s HBM. The LX scratchpad is 2 MB of on-core SRAM. There is no hardware cache. The compiler decides which tensors reside in LX at each point in the computation and emits explicit load/store instructions to move data.

Data moves between 128 GB of LPDDR5 and the 2 MB per-core LX scratchpad under explicit compiler control. There is no hardware cache.
Two sizing constraints matter for users:
2 MB LX scratchpad per core. Working sets that exceed this are staged in tiles. See Scratchpad Planning.
Per-core addressable device memory limit. This is a separate hardware address-space constraint, not the 2 MB LX size. Work division must keep each core’s footprint under this limit.
Note
The SuperDSC IR has a legacy field name hbm that refers to LPDDR5
device memory in general. Spyre’s device memory is LPDDR5, not HBM.
4. Sticks and tiled tensors
The unit of memory transfer on Spyre is a stick: 128 B aligned, 64 fp16
elements (BYTES_IN_STICK = 128). A stick matches the granularity of a
load between LPDDR5 and LX, so each transfer moves a full stick of
contiguous data.
Tensors on Spyre are therefore not stored the way PyTorch describes
them. A (1024, 256) fp16 tensor is physically four tiles of 64-element
sticks: (4, 1024, 64) on the device. The element at position [i, 63]
and the element at [i, 64] are not one stride apart. They sit in
different tiles.

A (1024, 256) tensor on the host becomes a (4, 1024, 64) tiled
structure on the device. The stride breaks at every tile boundary, so
the layout cannot be expressed as a single integer stride per dimension.
PyTorch’s (size, stride) model cannot describe this layout, so
Torch-Spyre introduces FixedTiledLayout, a subclass of Inductor’s
FixedLayout that carries a SpyreTensorLayout descriptor with the
device-side shape and a host-to-device stride map. Two compiler
operations manage this layout:
Stickification is the transformation from a host-strided layout to a tiled device layout. It runs during layout propagation.
Restickification (
spyre::restickify) is an explicit re-tile the compiler inserts when two adjacent ops disagree on tile structure.
For the full reference, see Tensor Layouts.
5. Eager vs compiled path
A PyTorch program reaches Spyre on one of two paths. Which path a given line of code takes determines its performance.
Eager path. When you write x.to("spyre") or torch.add(x, y) on
Spyre tensors, PyTorch’s dispatcher routes each op to a Torch-Spyre C++
kernel registered against the PrivateUse1 device key. Each op runs
immediately. The result is correct but slow: there is no fusion, no
shared scratchpad reuse across ops, and many ops fall back to CPU.
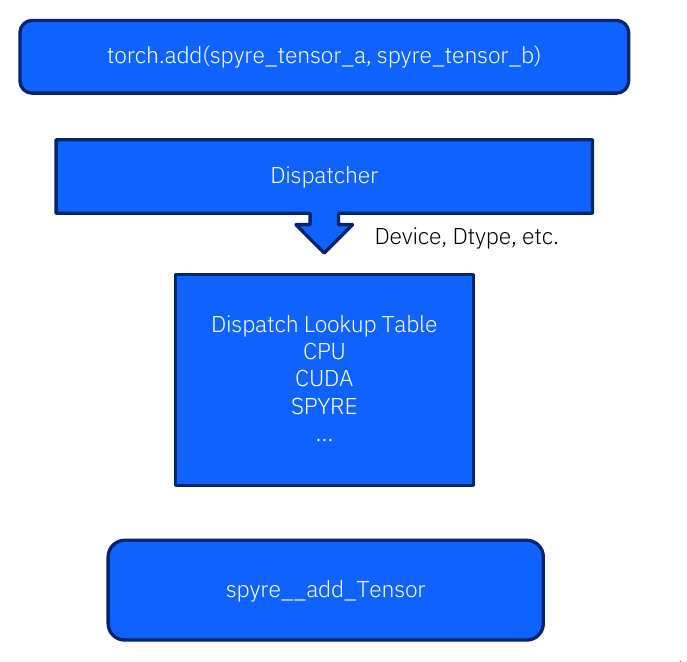
The eager path: the PyTorch dispatcher looks up the SPYRE entry in
its dispatch table for each op and calls the registered Spyre kernel.
Compiled path. When you wrap a model with
torch.compile(model, backend="spyre"), the FX graph passes through
the Torch-Spyre Inductor backend, which runs layout propagation,
work division, and scratchpad planning, then emits a SuperDSC artifact
that the Deeptools backend turns into a device binary.
import torch
import torch_spyre # registers the device
model = ... # any nn.Module
model = model.to("spyre")
compiled = torch.compile(model, backend="spyre")
out = compiled(x.to("spyre")) # this is the fast path
If you only want to test that something runs, the eager path is fine. For performance you must reach the compiled path. All Spyre-specific optimizations (tiled layouts, multi-core work division, LX planning) are implemented there.
6. Graph breaks
Inside a torch.compile-d region, anything Inductor cannot lower forces
a graph break: the compiled graph stops, the partial result
round-trips to the CPU, the unsupported op runs there, and the data
comes back. A single graph break in the hot path removes the
performance gains from the surrounding compiled code.
The most common cause is a missing op. Torch-Spyre handles ops in four layers, in priority order:

Op coverage on Spyre. ATen ops are decomposed into native ops or custom ops; custom ops lower to SuperDSC; everything else falls back to the CPU.
Native ops — ATen ops Deeptools supports directly (pointwise ops,
mm,bmm).Custom ops — Spyre-specific ops registered via
torch.library.custom_op(e.g.spyre::rms_norm,spyre::layer_norm,spyre::gelu).Decompositions — FX rewrites that turn an ATen op into a sequence of native or custom ops (e.g.
aten.addmm→matmul + scale + add).CPU fallback — auto-transfer for the long tail (
embedding,arange,sin,cos,tril,triu, …). Transparent, but off the hot path only.
When debugging slow models, the first question to ask is whether anything fell through to the CPU fallback. See Supported Operations for the current matrix and Adding Operations to enable a new one.
7. Compilation pipeline
The compiled path runs the standard PyTorch pipeline (FX capture,
AOTAutograd, Inductor scheduler) and inserts three Spyre-specific
passes: layout propagation, work division (span_reduction followed
by work_distribution), and scratchpad / LX planning. The output is
a SuperDSC JSON artifact that the Deeptools backend (a proprietary
compiler) turns into a device binary.

The compilation pipeline. Spyre-specific passes (orange) operate on two IR levels: the FX graph (before Inductor lowering) and the LoopLevel IR (before codegen). Gray boxes are PyTorch-standard.
IR levels
The compilation flow runs through several IRs in sequence:

Each box is a distinct IR. The pass between two boxes is named above the arrow: Dynamo, AOTAutograd, Inductor, codegen, and prepareKernel.
SuperDSC is the current Spyre kernel IR. It is JSON. One artifact per scheduled kernel encodes the per-core schedule, tensor descriptors, and the compute op. Artifacts are cached through the standard
torch.compilecache.KTIR is the planned successor, an MLIR-based dialect designed as a community specification for dataflow accelerators. See RFC 0682 for the specification.
SpyreCode is the runtime-side contract: a
JobPlanof ordered steps (host-to-device transfers, compute, host-side program correction, device-to-host transfers) thatSpyreStream::launchconsumes. SpyreCode is the runtime interface that turns a compiled kernel IR into device execution. See Runtime.
Named dimensions and tiling hints
Working set reduction is driven by named dimensions. User code
declares dimension names with declare_tensor_dim, attaches them to
input tensors with name_tensor_dims, and tiles them inside a
with spyre_hint(tiles={...}): scope. Hints are lexically scoped, can
be nested, and compose by intersection of the op’s iteration dimensions
with each enclosing hint’s tile dict. Full details and examples are in
Working Set Reduction.
For the full pipeline reference, see Compiler Architecture and Inductor Frontend.
8. Dtype defaults and casting
Spyre’s default compute dtype is torch.float16, so tensors created
without an explicit dtype are fp16. The dtype that is silently narrowed
with a warning is int64: Spyre has no 64-bit integer type, so int64
tensors are down-cast to int32, which can change values outside the
32-bit range. The warning is emitted once by default. Set
TORCH_SPYRE_DOWNCAST_WARN=0 (or call
torch.spyre.set_downcast_warning(False)) to suppress it. float32,
bfloat16, fp8 variants, and other dtypes are supported in the runtime
but have narrower op coverage on the compiled path, where explicit
fp32↔fp16 cast ops handle conversions.
If your model has a numerically sensitive layer, check the supported operations matrix for that op’s dtype coverage.
9. Running models today: FMS vs stock HuggingFace
Today the production path for LLM inference on Spyre is through IBM’s Foundation Model Stack (FMS), which provides Spyre-aware model implementations. Granite 3.3 8B runs in production this way:
from fms.models import get_model
model = get_model("granite", "3.3-8b-instruct", device_type="spyre")
compiled = torch.compile(model, backend="spyre")
This describes the state of the stack today and will change as the
stack matures. Once op coverage broadens, dynamic shapes land, and
KV-cache handling stabilizes, the same workloads will run with stock
AutoModelForCausalLM.from_pretrained(...).to("spyre") plus
torch.compile and no model-side changes. The FMS path will remain
supported and will become one of several entry points. If you are
running a model that FMS already supports, use FMS today. If you are
prototyping a new architecture, target the compiled path directly and
expect to file ops as you go. Check this page or the
supported operations matrix
for the current state.
10. Hardware constraints checklist
Constraints that show up as compile-time errors or unexpected behavior:
Constraint |
What it means in practice |
|---|---|
128-byte alignment |
Inner dimensions are padded up to a multiple of 64 fp16 elements (a stick). |
No HW scalar immediates |
Scalar constants in the FX graph are rewritten to size-1 tensors via |
Indivisible reduction dims |
Some reduction dimensions cannot be split across cores; work distribution honors this. |
Static shapes |
Dynamic shapes are work-in-progress. Shape-polymorphic models may recompile per shape. |
Per-core memory span (256 MB) |
Each core’s contiguous device-memory footprint must fit within 256 MB of addressable range. Separate from the 2 MB LX scratchpad capacity. |
fp16 default |
int64 is down-cast to int32 with a warning. Set |
|
Default core count; lowering it for debugging changes work-division decisions. |
11. Streams
Each Spyre device exposes asynchronous execution through stream
primitives that match the torch.cuda.Stream API:
import torch
s = torch.spyre.Stream()
with torch.spyre.stream(s):
out = compiled(x.to("spyre"))
torch.spyre.synchronize()
Streams are FIFO: operations submitted to the same stream complete
in order, while operations on different streams may execute
concurrently when the hardware allows it. Each device keeps a fixed
pool of streams (32 low-priority, 32 high-priority) plus a default
stream (stream 0). Priority is binary, not graded.
Full reference: Runtime — Streams.
12. Distributed execution
Multiple Spyre cards on the same host coordinate through the
spyreccl torch.distributed backend:
import torch
import torch.distributed as dist
dist.init_process_group(backend="cpu:gloo,spyre:spyreccl")
DEVICE = torch.device(f"spyre:{os.getenv('RANK', '0')}")
x = torch.zeros(1024, dtype=torch.float16, device=DEVICE)
dist.broadcast(x, src=0)
The model is one-device-per-process. Each rank attaches to a single
Spyre device. Implemented synchronous collectives include send,
recv, broadcast, barrier, gather, allgather, reduce, and
allreduce. The underlying transport library is closed-source IBM
code. Only the public adapter (SpyreCCLBackend in
csrc/distributed/) is in-tree.
Full reference: Runtime — Multi-card and distributed execution.
Where to go next
Run something end to end: Quickstart.
Learn the design story behind these concepts: How Torch-Spyre works.
Look up a single term: Glossary.
Dig into a specific area: Tensor Layouts, Compiler Architecture, Runtime.